
介绍一下自己
项目八股
回放数据是什么形式?项目挑战点?怎么解决的?断点续传的实现方式?如何确定哪些分片没有上传?
断点续传是指在上传或下载文件时,如果因为网络等原因导致传输中断,可以在下次传输时从上次中断的位置继续传输,而不需要重新传输整个文件。实现断点续传的方式有多种,其中比较常见的方式是使用文件分片和记录已上传分片的方式。具体实现方式如下:
将文件分成多个固定大小的分片,每个分片的大小一般为几十 KB 到几 MB 不等。
在上传或下载文件时,记录已经上传或下载的分片编号和偏移量,以便下次继续传输。
如果传输中断,下次传输时从上次中断的位置继续传输,只需要传输未上传或未下载的分片即可。
如何确定哪些分片没有上传或下载,可以通过记录已上传或已下载的分片编号和偏移量来实现。在上传或下载文件时,每传输一个分片就记录一下该分片的编号和偏移量,以便下次继续传输。如果传输中断,下次传输时只需要传输未上传或未下载的分片即可,可以根据已上传或已下载的分片编号和偏移量来确定哪些分片没有上传或下载。本项目通过文件分片的MD5值来判断分片是否已经上传或下载,如果分片的MD5值已经存在,则说明该分片已经上传或下载,否则说明该分片没有上传或下载。
redis做缓存,数据丢失怎么办?
首先知道redis数据丢失的原因如下:数据过期,进程崩溃,内存不足,主从同步延迟,redis服务器重启,集群节点下线,磁盘满了,数据被删除等等。
为缓解数据丢失的一部分方法:
- 1.设置合理的过期时间,避免数据过期,redis设置缓存的过期时间的方法:redis->setex(‘key’,30,’value’),这样设置的话,key的值30秒后就会过期,如果不设置过期时间,key的值就不会过期。
- 2.持久化,redis提供了两种持久化方式,一种是RDB,一种是AOF。RDB是指在指定的时间间隔内将内存中的数据集快照写入磁盘,AOF是指将每次写入的操作写入日志文件,以恢复数据。RDB的缺点是可能会丢失最后一次快照后的数据,AOF的缺点是每次写入都会同步到磁盘,影响性能。下面是这两种方法的配置:
//RDB
save 900 1
save 300 10
save 60 10000
这三行配置分别表示当900秒之内至少修改一次数据之后,保存一次数据;当300秒之内至少修改10次数据之后,保存一次数据;当60秒之内至少修改10000次数据之后,保存一次数据。
//AOF
appendonly yes
appendfilename “appendonly.aof”
appendfsync everysec
这三行配置开启了AOF,并设置了AOF持久化文件的名称为appendonly.aof,每隔一秒就将AOF的缓冲区刷新到磁盘中- 3.集群化,redis提供了集群化的方案,可以将数据分布在多个节点上,这样即使某个节点宕机,也不会导致数据丢失。
// 集群化配置
cluster-enabled yes
cluster-config-file /etc/redis/6379/nodes.conf
cluster-node-timeout 15000
这三行配置开启了集群化,并设置了集群化的配置文件为nodes.conf,设置了节点超时时间为15秒。- 4.Redis持久化加延时双删:在Redis持久化的基础上,加上延时双删机制,即在删除缓存时,不是立即删除,而是先记录下来,然后延时一段时间再删除,如果这段时间内,Redis宕机了,那么就可以通过记录进行数据恢复。
//延时双删
public void delete(String key) {
redisTemplate.delete(key);
sleep(100, TimeUnit.MILLISECONDS);
redis->set(‘key’,’new_value’);
}- 5.数据的物理备份
更多详细信息可以看这篇文章:Redis数据”丢失”讨论及规避和解决的几点总结
redis的数据结构
redis是单线程的吗?为什么这么快?
是单线程的,所有的客户端请求都是一个线程中处理的。官方提供的是最少10W+的QPS(每秒内查询次数)有以下几点优势:
- 避免了线程切换和竞争的开销
- 避免了多线程并发共享数据的问题,多线程共享数据时要使用锁机制来保证数据的一致性,而锁机制的开销是很大的
- 更好的利用CPU缓存,因为多线程并发共享数据时,数据会被保存在多个CPU缓存中,而CPU缓存的大小是有限的,如果数据量大的话,就会导致CPU缓存不够用,而单线程就不会有这个问题
redis快的原因:
1.完全基于内存的
2.采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多线程的切换开销和竞争开销,不存在加锁释放锁的开销,没有死锁的问题
3.使用多路I/O复用模型,非阻塞IO:Redis可以在单线程中监听多个Socket的请求,在任意一个Socket可读/可写时,Redis去读取客户端请求,在内存中操作对应的数据,然后再写回到Socket中,这样就避免了频繁的IO操作,避免了频繁的上下文切换,提高了性能
非CPU密集型,CPU不是Redis的瓶颈,Redis的瓶颈在于机器的内存和网络带宽。
Mysql调优经验
优化查询语句:使用合适的索引、避免使用通配符开头的LIKE查询、避免使用不必要的JOIN操作等,可以提高查询性能。
优化数据库结构:合理设计表结构,避免使用过多的冗余字段,使用合适的数据类型,避免使用过长的字段长度等。
合理配置缓冲区大小:根据服务器的内存大小和数据库的负载情况,调整合适的缓冲区大小,包括查询缓存、连接缓存、表缓存等。
使用合适的存储引擎:根据应用的需求和数据特点,选择合适的存储引擎,如InnoDB、MyISAM等。
合理配置日志:根据实际需求,开启适当的日志,如二进制日志、慢查询日志等,以便于故障排查和性能分析。
分区表:对于大表,可以考虑使用分区表来提高查询性能,将数据按照某个字段进行分区存储。
使用连接池:使用连接池可以减少连接的创建和销毁开销,提高数据库的并发性能。
定期维护数据库:定期进行数据库的备份、优化、碎片整理等维护工作,保持数据库的健康状态。
监控数据库性能:使用监控工具对数据库的性能进行实时监控,及时发现并解决性能问题。
升级数据库版本:根据实际情况,考虑升级数据库版本,以获取新功能和性能改进。
Mysql索引
详情可见博客图解Mysql
Mysql的隔离级别
- 读未提交(read uncommitted):一个事务还没提交时,它做的变更就能被别的事务看到。
- 读提交(read committed):一个事务提交之后,它做的变更才会被其他事务看到。
- 可重复读(repeatable read):一个事务执行过程中看到的数据,总是跟这个事务在启动时看到的数据是一致的。在可重复读隔离级别下,未提交变更对其他事务也是不可见的。
- 串行化(serializable):对于同一行记录,写会加写锁,读会加读锁。当出现读写锁冲突的时候,后访问的事务必须等前一个事务执行完成,才能继续执行。
MVCC
MVCC是一种并发控制的方法,用来解决读-写冲突。在MVCC协议下,每个读操作会看到一个一致性的snapshot,并且可以实现非阻塞的读。MVCC允许数据具有多个版本,这个版本可以是时间戳或者是全局递增的事务ID,在同一个时间点,不同的事务看到的数据是不同的。在读取数据的时候,不仅会读到最新的数据,还会读到所有已经提交的数据版本,然后使用undo log来构造一个一致性的snapshot。在可重复读隔离级别下,MVCC只会查找已经提交的数据版本,因此可以避免幻读的问题。
Java类加载机制
Java源程序(.java文件)在经过编译器编译之后被转换成字节代码(.class 文件),类加载器将.class文件中的二进制数据读入到内存中,将其放在方法区内,然后在堆区创建一个java.lang.Class对象,用来封装类在方法区内的数据结构
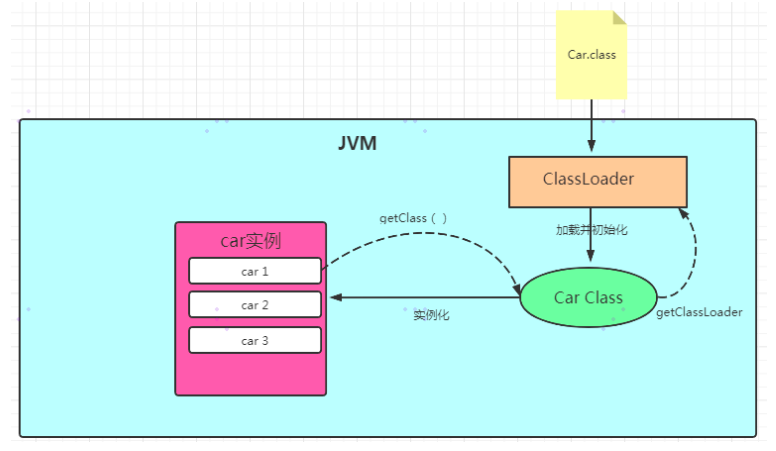
加载:通过一个类的全限定名来获取定义此类的二进制字节流。将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构。在Java堆中生成一个代表这个类的java.lang.Class对象,作为对方法区中这些数据的访问入口。加载阶段完成后,虚拟机外部的二进制字节流就按照虚拟机所需的格式存储在方法区之中,而且在Java堆中也创建一个java.lang.Class类的对象,这样便可以通过该对象访问方法区中的这些数据。
验证:分为四步:文件格式验证、元数据验证、字节码验证、符号引用验证。如果所引用的类经过反复验证,可以考虑使用-Xverify:none参数来关闭大部分的类验证措施,以缩短虚拟机类加载的时间。
准备:为类的静态变量分配内存,并初始化默认值,这些内存是在方法区中分配,需要注意以下几点:1.此处内存分配的变量仅包含类变量(static),而不包括实例变量,实例变量会随着对象实例化被分配在java堆中。2.这里默认值是数据类型的默认值(如0、0L、null、false),而不是代码中被显示的赋予的值。3.如果类字段的字段属性表中存在ConstatntValue属性,即同时被final和static修饰,那么在准备阶段变量value就会被初始化为ConstValue属性所指定的值。
解析:虚拟机将常量池内的符号引用替换为直接引用的过程,解析动作主要针对类或接口、字段、类方法、接口方法、方法类型、方法句柄和调用点限定符7类符号引用进行。符号引用就是一组符号来描述目标,可以是任何字面量。
初始化:为类的静态变量赋予正确的初始值,JVM负责对类进行初始化,主要对类变量进行初始化。初始化阶段是执行类构造器()方法的过程。
双亲委派机制:当一个类加载器收到了类加载的请求时,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成,每一个层次的类加载器都是如此,因此所有的加载请求都应该传送到启动类加载器中,只有当父类加载器反馈自己无法完成这个加载请求时(它的搜索范围中没有找到所需的类),子加载器才会尝试自己去加载。
一次完整的HTTP请求过程
- DNS解析:将域名解析为IP地址
- 三次握手:建立TCP连接
- 发送HTTP请求
- 服务器处理请求并返回HTTP报文
- 四次挥手:断开TCP连接
get和post的区别,get支持哪些编码
get和post本质上都是TCP连接,并无差别,但是由于HTTP协议,和浏览器/服务器的限制,导致get和post在一些方面有所区别。
- GET 请求只能 URL 编码,而 POST 支持多种编码方式
- GET 请求只接受 ASCII 字符的参数,而 POST 则没有限制
- GET 请求的参数通过 URL 传送,而 POST 放在 Request Body 中
- GET 相对于 POST 更不安全,因为参数直接暴露在 URL 中
- GET 请求会被浏览器主动缓存,而 POST 不会(除非自己手动设置)
- GET 请求在 URL 传参有长度限制,而 POST 则没有限制
- GET 产生的 URL 地址可以被收藏,而 POST 不可以
- GET 请求的参数会被完整的保留在浏览器的历史记录里,而 POST 的参数则不会
- GET 在浏览器回退时是无害的,而 POST 会再次提交请求
- GET产生一个TCP数据包,POST产生两个TCP数据包,但是在Firefox浏览器下,如果使用POST提交表单时,浏览器会优化成GET请求,所以只产生一个TCP数据包
Spring循环依赖
三个或三个以上的bean之间相互依赖,形成一个闭环,这种情况下就会发生循环依赖。Spring在实例化一个bean的时候,是首先递归的实例化其所依赖的所有bean,直到某个bean没有依赖其他bean,然后将该实例化返回,然后反递归的将获取的bean设置为各个上层bean的属性。
解决循环依赖是由前置条件的:首先出现循环依赖的bean必须是单例的也就是singleton,其次循环依赖的bean不能全是构造器注入,必须有一个是setter注入。
Spring解决循环依赖一般是通过三级缓存来实现的,三级缓存分别是singletonFactories、earlySingletonObjects、singletonObjects。singletonFactories用于存放bean的工厂,earlySingletonObjects用于存放bean的早期引用,singletonObjects用于存放bean的最终实例。
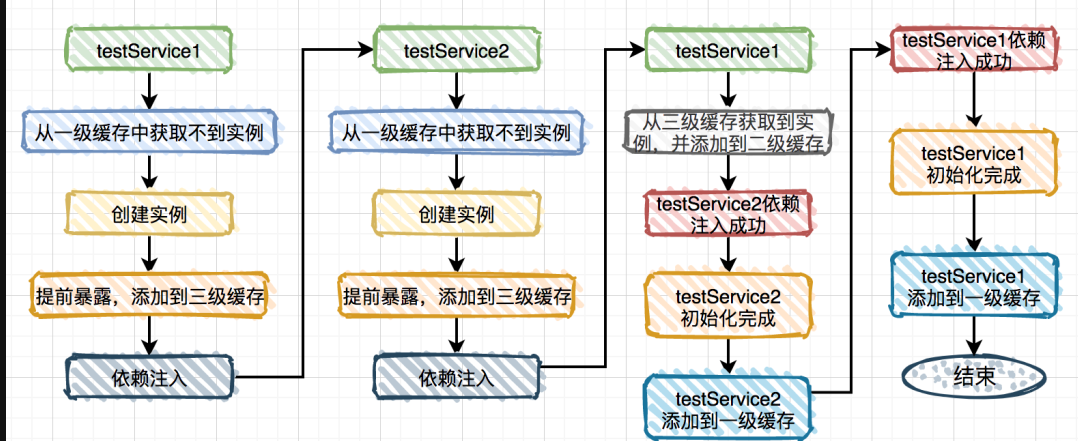
具体流程:
Spring通过三级缓存解决了循环依赖,其中一级缓存为单例池(singletonObjects),二级缓存为早期曝光对象earlySingletonObjects,三级缓存为早期曝光对象工厂(singletonFactories)。
当A、B两个类发生循环引用时,在A完成实例化后,就使用实例化后的对象去创建一个对象工厂,添加到三级缓存中,如果A被AOP代理,那么通过这个工厂获取到的就是A代理后的对象,如果A没有被AOP代理,那么这个工厂获取到的就是A实例化的对象。
当A进行属性注入时,会去创建B,同时B又依赖了A,所以创建B的同时又会去调用getBean(a)来获取需要的依赖,此时的getBean(a)会从缓存中获取。
- 先获取到三级缓存中的工厂;
- 调用对象工工厂的getObject方法来获取到对应的对象,得到这个对象后将其注入到B中。紧接着B会走完它的生命周期流程,包括初始化、后置处理器等。
- 当B创建完后,会将B再注入到A中,此时A再完成它的整个生命周期。至此,循环依赖结束!
Linux查看一个字符串在文件中出现了几次使用什么命令
在Linux中,可以使用grep命令来查看一个字符串在文件中出现了几次。grep命令用于在文件中查找指定的模式或字符串,并将匹配的行打印出来。
命令格式如下:
grep -c “字符串” 文件名
其中,-c选项用于统计匹配到的行数。
举个例子,假设要查找文件example.txt中字符串hello出现的次数,可以使用以下命令:
grep -c “hello” example.txt
执行命令后,终端会输出字符串hello在文件example.txt中出现的次数。
垃圾回收算法
Java 垃圾回收算法是指在 Java 虚拟机中,用于自动回收无用对象的算法。Java 垃圾回收算法的主要目的是释放内存空间,避免内存泄漏和内存溢出等问题。
Java 垃圾回收算法主要有以下几种:
标记-清除算法(Mark and Sweep):该算法分为标记和清除两个阶段。在标记阶段,垃圾回收器会遍历所有的对象,并标记出所有需要回收的对象。在清除阶段,垃圾回收器会清除所有被标记的对象,并释放它们所占用的内存空间。该算法的缺点是会产生内存碎片,影响程序的性能。
复制算法(Copying):该算法将内存空间分为两个区域,每次只使用其中一个区域。当一个区域被占满时,垃圾回收器会将所有存活的对象复制到另一个区域中,并清除原来的区域。该算法的优点是不会产生内存碎片,但缺点是需要额外的内存空间。
标记-整理算法(Mark and Compact):该算法分为标记和整理两个阶段。在标记阶段,垃圾回收器会遍历所有的对象,并标记出所有需要回收的对象。在整理阶段,垃圾回收器会将所有存活的对象移动到内存的一端,并清除另一端的所有对象。该算法的优点是不会产生内存碎片,但缺点是需要移动对象,影响程序的性能。
分代算法(Generational):该算法将内存空间分为多个代,每个代的对象具有不同的生命周期。新创建的对象会被分配到年轻代,年轻代满了之后会触发一次垃圾回收,将存活的对象复制到存活区。存活区满了之后会触发一次垃圾回收,将存活的对象移动到老年代。老年代满了之后会触发一次 Full GC,清除所有无用对象。该算法的优点是可以根据对象的生命周期进行优化,提高程序的性能。
以上是 Java 垃圾回收算法的主要内容。在实际开发中,需要根据具体的应用场景选择合适的垃圾回收算法,以提高程序的性能和稳定性。
如何判断对象可回收?
- 引用计数法:给对象添加一个引用计数器,每当有一个地方引用它时,计数器值就加1;当引用失效时,计数器值就减1;任何时刻计数器为0的对象就是不可能再被使用的。由于循环引用的存在,因此JAVA虚拟机不使用引用计数法。
- 可达性分析法:通过一系列的称为“GC Roots”的对象作为起始点,从这些节点开始向下搜索,搜索所走过的路径称为引用链,当一个对象到GC Roots没有任何引用链相连时,则证明此对象是不可用的。
有哪些锁,锁升级的过程
四种状态:无锁,偏向锁,轻量级锁,重量级锁,锁升级的过程是逐渐升级的,不可逆的。
锁升级的过程:无锁->偏向锁->轻量级锁->重量级锁
手写快排
//快排
import java.util.Arrays;
public class Quik {
public static void quickSort(int[] arr, int low, int high) {
if (low < high) {
int index = getIndex(arr, low, high);
quickSort(arr, low, index - 1);
quickSort(arr, index + 1, high);
}
}
/**
* 获取数组中的分区点
* @param arr 待排序数组
* @param low 分区起始位置
* @param high 分区结束位置
* @return 分区点位置
*/
public static int getIndex(int[] arr, int low, int high) {
int pivot = arr[low];
while (low < high) {
while (low < high && arr[high] <= pivot) {
high--;
}
arr[low] = arr[high];
while (low < high && arr[low] >= pivot) {
low++;
}
arr[high] = arr[low];
}
arr[low] = pivot;
return low;
}
public static void main(String[] args) {
int[] arr = { 3, 5, 2, 1, 4, 6, 7, 8, 9, 10 };
quickSort(arr, 0, arr.length - 1);
System.out.println(Arrays.toString(arr));
}
}