
1. 项目介绍
基于springboot+springcloud+vue的微服务图书馆项目,主要包括以下几个模块:
- 登录验证服务:用于处理用户注册、登录、密码重置等,反正就是一切与账户相关的内容,包括用户信息获取等。
- 图书管理服务:用于进行图书添加、删除、更新等操作,图书管理相关的服务,包括图书的存储等和信息获取。
- 图书借阅服务:交互性比较强的服务,需要和登陆验证服务和图书管理服务进行交互。
- 秒杀模块:用户可以在秒杀模块参与秒杀活动
2. 数据库设计
用户表:user
| 字段名 | 类型 | 说明 |
|---|---|---|
| id | int | 用户id |
| username | varchar | 用户名 |
| password | varchar | 密码 |
| age | int | 年龄 |
| sex | int | 性别 |
| varchar | 邮箱 | |
| phone | varchar | 手机号 |
| role | int | 用户角色 |
| status | int | 用户状态 |
| create_time | datetime | 创建时间 |
| update_time | datetime | 更新时间 |
| last_login_time | datetime | 最后登录时间 |
| last_login_ip | varchar | 最后登录ip |
图书表:book
| 字段名 | 类型 | 说明 |
|---|---|---|
| id | int | 图书id |
| name | varchar | 图书名 |
| author | varchar | 作者 |
| price | double | 价格 |
| stock | int | 库存 |
| sales | int | 销量 |
| img_path | varchar | 图片路径 |
| create_time | datetime | 创建时间 |
| update_time | datetime | 更新时间 |
| description | varchar | 图书描述 |
借书表:borrow
| 字段名 | 类型 | 说明 |
|---|---|---|
| id | int | 借书id |
| user_id | int | 用户id |
| book_id | int | 图书id |
| borrow_time | datetime | 借书时间 |
| return_time | datetime | 还书时间 |
| status | int | 借书状态 |
订单表:order
| 字段名 | 类型 | 说明 |
|---|---|---|
| id | int | 订单id |
| user_id | int | 用户id |
| book_id | int | 图书id |
| book_name | varchar | 图书名 |
| create_time | datetime | 创建时间 |
| update_time | datetime | 更新时间 |
| status | int | 订单状态 |
秒杀表:seckill
| 字段名 | 类型 | 说明 |
|---|---|---|
| id | int | 秒杀id |
| book_id | int | 图书id |
| start_time | datetime | 开始时间 |
| end_time | datetime | 结束时间 |
| create_time | datetime | 创建时间 |
| update_time | datetime | 更新时间 |
| version | int | 版本号 |
| stock | int | 库存 |
秒杀订单表:seckill_order
| 字段名 | 类型 | 说明 |
|---|---|---|
| id | int | 秒杀订单id |
| user_id | int | 用户id |
| order_id | int | 订单id |
| book_id | int | 图书id |
| create_time | datetime | 创建时间 |
| update_time | datetime | 更新时间 |
| status | int | 订单状态 |
库存表:stock
| 字段名 | 类型 | 说明 |
|---|---|---|
| id | int | 库存id |
| book_id | int | 图书id |
| stock | int | 库存 |
| sale | int | 销量 |
| borrow | int | 借阅量 |
3. 项目技术难点
3.1 项目架构
项目采用前后端分离的架构,前端使用vue,后端使用springboot+springcloud,前后端通过http协议进行通信,前端通过axios发送http请求,后端通过springcloud的feign进行服务间的调用,后端通过springcloud的gateway进行路由转发,前端通过nginx进行负载均衡,后端通过springcloud的ribbon进行负载均衡
服务间的远程调用:通过RestTemplate和Feign进行远程调用,RestTemplate是spring提供的用于访问Rest服务的客户端,Feign是一个声明式的Web服务客户端,它使得编写Web服务客户端变得更加简单。
服务间的负载均衡:通过Ribbon和Nginx进行负载均衡,Ribbon是一个客户端负载均衡器,它可以很好的控制HTTP和TCP客户端的行为,Nginx是一个高性能的HTTP和反向代理服务器,可以实现负载均衡、反向代理、动静分离等功能。
3.1 服务注册与发现
使用Nacos作为服务注册中心,Nacos是一个开源的动态服务发现、配置管理和服务管理平台,它可以帮助我们更好的实现微服务架构。使用OpenFeign实现服务远程调用以及负载均衡。在nacos集群服务前使用nginx实现一个SLB,DNS解析到nginx,nginx再根据负载均衡策略将请求转发到nacos集群中的某个节点。
Nacos中的临时分区和非临时分区:
临时分区:和Eureka一样,采用心跳机制向Nacos发送请求保持在线状态,一旦心跳停止,代表实例下线,不保留实例信息。Nacos将其从服务列表中移除,不再向其发送请求。
非临时分区:由Nacos主动进行联系,如果连接失败,那么不会移除实例信息,而是将健康状态设定为false。当实例重新上线时,Nacos会将健康状态设定为true。相对于Nacos会对这个实例状态持续进行监控
Sentinel限流
Sentinel是阿里巴巴开源的一款流量控制组件,它具有以下特点:
- 丰富的应用场景:Sentinel承接了阿里巴巴近10年的双十一大促流量的核心场景,例如秒杀、高并发等场景,Sentinel提供了流量控制、熔断降级、系统负载保护等功能,帮助我们保护系统的稳定性。
- 完备的实时监控:Sentinel提供了实时的监控功能,可以实时的查看系统的运行状态,例如QPS、线程池状态、集群节点状态等。
- 广泛的开源生态:Sentinel提供了与Spring Cloud、Dubbo、gRPC等开源生态的整合,可以很方便的与这些开源生态进行集成。
- 完善的SPI扩展点:Sentinel提供了完善的SPI扩展点,可以很方便的扩展自定义的逻辑。
流量控制选择的策略是预热限流,预热限流是指系统启动时,不会直接限制流量,而是先将系统的阈值慢慢的增加,直到达到设置的QPS阈值。预热限流的好处是可以在系统启动时逐渐增加系统的阈值,避免系统启动时流量突增,导致系统瞬间被压垮。
判断流量是否超过流量阈值的方法是令牌桶算法,令牌桶算法是一种流量整形算法,它可以控制数据传输的速率,平滑网络上的突发流量。令牌桶算法的原理是系统会以一个恒定的速度往桶里放入令牌,而如果请求需要被处理,则需要先从桶里获取一个令牌,当桶里没有令牌可取时,则拒绝服务。
服务熔断和降级:都是基于信号量隔离。熔断规则是基于异常比例或异常数来触发熔断及恢复,降级规则是基于响应时间来触发降级及恢复。服务降级之后选择的策略是返回一个友好的提示信息,例如“当前系统繁忙,请稍后再试”。
Seata分布式事务
Seata是一款开源的分布式事务解决方案,它提供了AT、TCC、SAGA和XA等多种事务模式,可以很好的满足不同的分布式事务场景。Seata提供了高性能和高可用的分布式事务服务。主要由三部分组成:事务协调器(TC)、事务管理器(TM)和资源管理器(RM)。
RM: 用于直接执行本地事务的提交和回滚
TM: 核心管理者,用于全局事务的开启、提交和回滚
TC:用于全局事务的协调者,用于全局事务的提交和回滚
流程:TM请求TC开启一个全局事务,TC会生成一个XID作为该全局事务的编号,XID会在微服务的调用链路中传播,保证将多个微服务的子事务关联在一起;RM请求TC将本地事务注册为全局事务的分支事务,通过全局事务的XID进行关联;TM请求TC告诉XID对应的全局事务是进行提交还是回滚;TC驱动RM将XID对应的自己的本地事务进行提交还是回滚;
部署方式
使用本地Seata服务的file模式部署,配合Nacos实现分布式事务。Seata的file模式是指将Seata的配置文件存储在本地,Seata的配置文件包括registry.conf、file.conf和config.txt,registry.conf是注册中心的配置文件,file.conf是Seata的配置文件,config.txt是Seata的配置文件,它包含了Seata的事务日志存储位置、事务日志文件大小、事务日志文件个数等信息。
- 单独为Seata配置一个命名空间
- 打开conf目录下的registry.conf文件,修改registry.type为nacos,修改registry.nacos.serverAddr为nacos的地址,修改registry.nacos.namespace为Seata的命名空间
- 将配置文件上传到nacos中,让Nacos管理配置文件,这样就实现了对配置文件的热更新
- 在客户端也要进行Nacos配置
分布式权限校验
单点登陆使用OAuth2.0实现,基于授权码模式处理。在springcloud中直接使用spring-security-oauth2实现,spring-security-oauth2是spring-security的扩展,它提供了一系列的扩展点,可以很方便的实现OAuth2.0的各种授权模式。为缓解验证服务器的压力,使用redis存储token,使用jwt进行token的生成和解析。
Redis中的分布式锁
由于加锁的超时时间不好手动设定,所以引入Redisson框架,Redisson是一个在Redis的基础上实现的Java驻内存数据网格(In-Memory Data Grid)。它不仅提供了一系列的分布式的Java常用对象,还提供了许多分布式服务。其中分布式锁就是其中的一个服务,它提供了一种非常便利的加锁和解锁的方式。
Redisson内部提供了一个监控锁的看门狗,它会在后台线程中启动一个定时任务,每隔一段时间就会检查一下当前线程是否还持有该锁,如果是的话就会延长锁的过期时间,如果不是的话就会释放该锁。这样就可以保证即使业务逻辑执行时间过长,也不会导致锁过期而被释放掉。
但是当某个存放锁的服务器挂掉了,那么锁就会失效,为了解决这个问题,引入了RedLock算法,RedLock算法是Redis作者提出的一种分布式锁算法,它的原理是:当某个服务器要获取锁时,会向N个Redis节点获取锁,如果大多数的Redis节点都能成功获取锁,那么就认为获取锁成功,否则获取锁失败。RedLock算法的优点是可以避免单点故障,缺点是会增加锁的获取时间。
MySQL的分库分表
使用Sharding JDBC实现分库分表,Sharding JDBC是一个基于JDBC的分布式数据库中间件,它对JDBC的标准接口进行了增强,可以在不修改原有业务逻辑的基础上实现分库分表。Sharding JDBC的原理是将SQL解析为多个子SQL,然后将子SQL发送到不同的数据库中执行,最后将执行结果进行汇总。Sharding JDBC提供了两种分片策略:标准分片策略和复合分片策略。标准分片策略是指将SQL中的某个字段的值进行取模,然后根据取模的结果将SQL发送到不同的数据库中执行。复合分片策略是指将SQL中的多个字段的值进行组合,然后根据组合的结果将SQL发送到不同的数据库中执行。
垂直拆分:将一个大的数据库拆分为多个小的数据库,每个数据库只包含一部分表,例如将用户表和图书表拆分为两个数据库,用户数据库只包含用户表,图书数据库只包含图书表。垂直拆分的好处是可以将不同的业务拆分到不同的数据库中,避免了数据库的冗余,但是也带来了一些问题,例如跨库的join操作,需要通过分布式事务来保证数据的一致性。
水平拆分:将一个大的表拆分为多个小的表,每个表只包含一部分数据,例如将用户表拆分为多个用户表,每个用户表只包含一部分用户数据。水平拆分的好处是可以将数据分散到不同的表中,避免了单表数据量过大的问题,但是也带来了一些问题,例如跨表的join操作,需要通过分布式事务来保证数据的一致性。
本项目使用的基于取模的方式实现分库分表,将用户表和图书表拆分为多个小的表,每个表只包含一部分数据,例如用户表拆分为user_0、user_1、user_2等,图书表拆分为book_0、book_1、book_2等。
分布式事务ID使用雪花算法:雪花算法是Twitter开源的分布式ID生成算法,它可以保证在分布式环境中生成唯一的ID,而且整个ID是趋势递增的。雪花算法的核心思想是:使用一个64位的long型的数字作为全局唯一ID,这64位中,其中1位是不用的,用作符号位,不可用;41位用作毫秒数,可以使用69年;10位用作工作机器id,可以部署在1024个节点;12位用作序列号,1ms内可以生成4096个id。
RabbitMQ消息队列
死信队列:死信队列是指当消息在一个队列中变成死信(dead message)之后,它能被重新发送到另一个交换机中,这个交换机就是死信队列。死信队列的好处是可以将一些无法被消费的消息转发到另一个交换机中,然后再由另一个消费者进行消费,避免了消息的丢失。在RabbitMQ中,当消息满足以下三种情况时,就会变成死信:
- 消息被拒绝,并且设置了requeue=false
- 消息过期
- 队列达到最大长度
当队列达到最大长度时,位于队列开头的消息会被丢弃或者发送到死信队列中,这取决于队列的模式。在RabbitMQ中,队列有两种模式:普通队列和优先级队列。普通队列是先进先出的,当队列达到最大长度时,位于队列开头的消息会被丢弃。优先级队列是按照优先级进行消费的,当队列达到最大长度时,优先级低的消息会被丢弃,优先级高的消息会被发送到死信队列中。
超卖问题
为防止用户刷单,使用了两个方法:
- 抢购接口隐藏
- 限制用户访问频率:使用redis记录用户访问的次数,当用户访问次数超过一定的阈值时,就不允许用户访问抢购接口。
测试数据:2核4G大小的云服务器,使用jmeter进行压测,单台服务器在使用缓存的情况下,吞吐量大概为2200请求每秒。
保证数据一致性:采用最终一致性的方案,将用户的秒杀请求放入消息队列中,然后由消费者进行消费,消费者会将用户的秒杀请求写入数据库中,这样就可以保证数据的一致性。
XA分布式事务协议-2PC
- 准备阶段:协调者向所有参与者发送prepare请求,参与者执行事务操作,写入undo和redo日志,但是不提交事务,然后向协调者发送响应。如果参与者成功执行事务操作,则返回ok,否则返回no。
- 提交阶段:如果协调者收到所有参与者的响应都是ok,则向所有参与者发送commit请求,参与者收到commit请求后,执行事务提交操作,释放所有事务资源,然后向协调者发送响应。如果参与者成功执行事务提交操作,则返回ok,否则返回no。如果有一个执行者返回失败,那就让所有的执行者全部回滚。
存在的问题:2PC协议存在着阻塞问题,当参与者在等待协调者的响应时,会一直处于阻塞状态,这样会导致参与者的资源一直被占用,无法释放,从而导致系统的吞吐量降低。
XA分布式事务协议-3PC
就是上两阶段提交的基础上加入了超时机制,同时在协调者和执行者中都加入了超时机制,当超时发生时,会执行事务的回滚操作。
TCC分布式事务协议
TCC分布式事务协议是一种补偿型的分布式事务协议,它的核心思想是:将一个大的分布式事务拆分为多个小的本地事务,每个本地事务都有对应的try、confirm和cancel三个操作,当所有的本地事务都执行成功时,就执行confirm操作,当任何一个本地事务执行失败时,就执行cancel操作。TCC分布式事务协议的优点是可以很好的控制事务的边界,缺点是需要开发人员自己实现事务的try、confirm和cancel操作。
OAuth2.0四种授权模式
- 客户端模式:客户端直接向验证服务器请求一个Token,客户端使用Token向资源服务器请求资源。但是这种方式不适合于用户访问资源的场景,因为客户端直接向验证服务器请求Token,没有用户的参与,所以无法确定用户是否同意授权。只适合于服务内部的调用,例如微服务之间的调用。
- 密码模式:用户将用户名和密码发送给客户端,客户端使用用户名和密码向验证服务器请求Token,客户端使用Token向资源服务器请求资源。这种方式的优点是简单,缺点是客户端需要保存用户的用户名和密码,如果客户端被攻击,用户的用户名和密码就会泄露。
- 隐式授权模式:客户端直接访问对应的服务,然后对应的服务进行验证,如果此时没有获得授权,就重定向到验证服务器,用户自行登陆验证服务器,验证服务器验证成功后,重定向到客户端,客户端使用Token向资源服务器请求资源。对应的服务再将Token发给验证服务器验证,验证成功后,就可以访问资源。这种方式的优点是简单,缺点是Token直接暴露在URL中,容易被攻击。
- 授权码模式:相比隐式授权,它不会直接返回Token,而是返回授权码,这种的Token通过应用服务器访问验证服务器获得,应用服务器和验证服务器之间会共享一个secret,这个secret不会被其他人知道,而验证服务器在用户验证完成之后,会返回一个授权码,应用服务器最后将授权码和secret一起交给验证服务器进行验证,并且Token也是阿紫服务端之间传递的,不会给到客户端,这样就保证了Token的安全性。
使用JWT存储Token
JWT是一种轻量级的身份认证和信息传递的解决方案,它可以在用户和服务器之间传递安全可靠的信息。JWT由三部分组成:头部、载荷和签名。头部用于描述JWT的元数据,例如签名算法、类型等,载荷用于存放JWT的具体内容,例如用户的ID、用户名等,签名用于对JWT进行签名,防止JWT被篡改。JWT的优点是简单、安全、易于使用,缺点是Token无法废止,一旦泄露,就会导致安全问题。
RabbitMQ架构设计
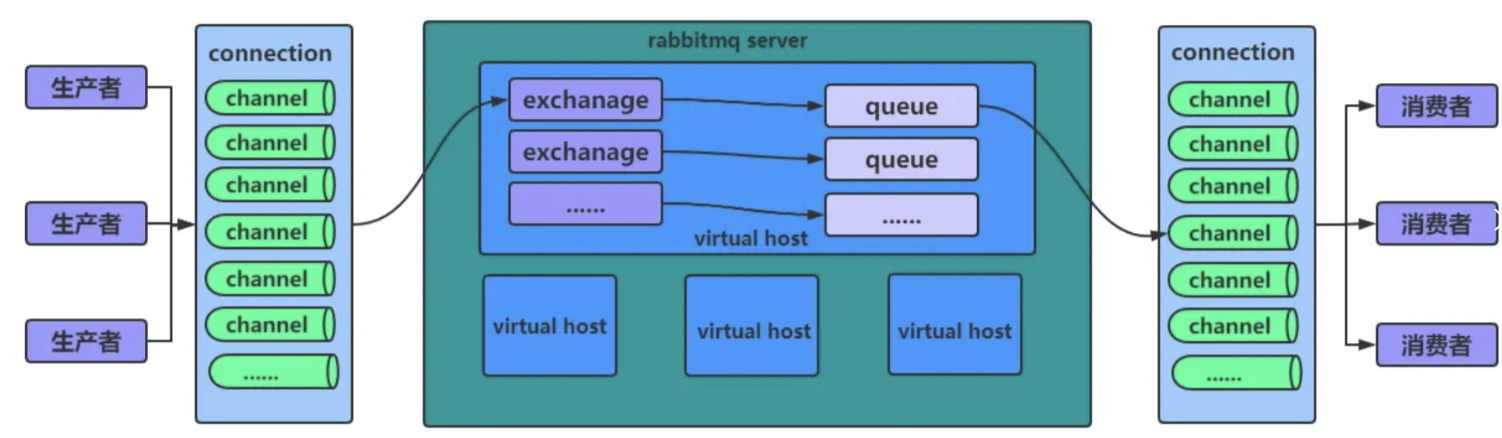
Exchange:类似于交换机的存在,会根据我们的请求转发响应的消息队列,每个队列都可以绑定在Exchange上,不同类型的Exchange可以用于实现不同消息的模式
Queue:消息队列的实体,生产者所有的消息都存放在消息队列中,等待消费者取出
Virtual Host:类似于环境隔离,不同的环境都可以单独配置一个Virtual Host,每个Virtual Host都有自己的Exchange、Queue和Binding
Binding:绑定,用于将Exchange和Queue进行绑定,Exchange和Queue之间的绑定关系称为Binding,Binding的作用是将消息路由到指定的队列中
消息队列的三种应答模式:
- Nack message request:拒绝消息,消息会被丢弃
- ACK message request:确认消息,消息会被消费,一次可以确认多个消息
- Reject message request:拒绝消息,但是可以指定是否重新入队
SpringCloud消息组件
- SpringCloud Stream:SpringCloud Stream是一个轻量级的消息中间件框架,它提供了一套标准的消息中间件开发模型,可以很方便的实现消息的发送和接收。SpringCloud Stream的核心概念是Binder,它是SpringCloud Stream的核心组件,它负责将应用程序和消息中间件进行绑定,SpringCloud Stream提供了多种Binder的实现,例如RabbitMQ、Kafka、RocketMQ等。屏蔽底层实现,统一消息的编程模型,可以很方便的切换消息中间件。
- SpringCloud Bus:SpringCloud Bus是一个事件、消息总线,它可以将分布式系统的节点连接起来,可以用于广播配置文件的更改或者服务之间的通讯,也可以用于监控。SpringCloud Bus的核心思想是利用消息总线触发一个服务,然后这个服务再去刷新其他服务的配置,所以它需要配合消息中间件来实现,SpringCloud Bus支持RabbitMQ和Kafka。