
虽然较大的卷积核或者使用较小的卷积块叠加可以增加感受野,但是这种方法会导致参数量的增加,而且对于大尺度的感受野,这种方法的效果并不好。因此,本文提出了一种新的方法,即特征收缩金字塔(FSP),它可以有效地增加感受野,同时保持较少的参数量。
当前使用VIT处理COD任务的方法存在两个主要的技术问题
1.VIT的局部建模效果不佳,本文认为其原因是全局特征和局部特征在COD中都具有较为重要的作用,但是目前的VIT方法缺乏在局部区域内进行行信息交互的机制。
2.解码器特征聚合的局限性,现有的解码器通常是直接聚合具有显著信息差异的特征,其倾向抛弃一些不明显但具有价值的线索或引入噪声。导致不准确的预测结果。
为此本文提出一种新颖的基于VIT的特征收缩金字塔网络旨在通过渐进收缩对伪装目标的局部增强全局表示的相邻VIT特征进行分层解码,从而在编码器和解码器中挖掘和积累丰富的伪装目标局部线索和全局上下文,实现伪装目标的精确检测。
Related Work
CNN-based COD
1.通过精心设计的特征搜索模块从背景中挖掘伪装对象的不显眼特征。
上下文特征学习
纹理感知学习
频域学习
2.在数据标记为COD伪装数据本身时对不确定性进行建模
3.多任务学习框架,引入辅助任务,提高伪装目标检测的性能,如边缘/边界检测,分类,对象排序等。
4.通过模仿捕食者的行为模式或视觉机制来检测伪装物体。如搜索和识别过程,以及放大和缩小的视觉机制。
5.利用运动信息在视频中发现伪装目标。
Decoding Strategy
SOD,MIS,COD等视觉任务的解码器设计可以归纳为四种类型:(1)U型解码结构,(2)密集集成策略(3)反馈细化策略(4)低层和高层特征的分离解码策略。
Proposed Method
总体架构如下图所示
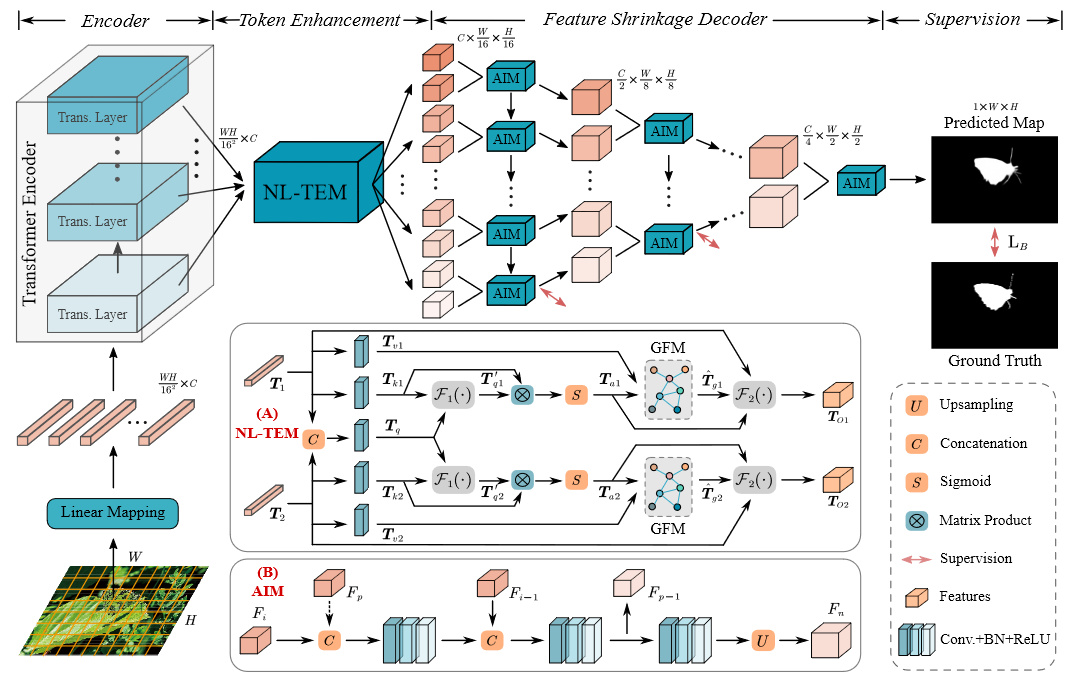
由VIT编码器,局部令牌增强模块和特征收缩解码器三部分组成。具体来说就是先将输入图片序列化为令牌后,作为VIT编码器的输入,使用自注意力机制对全局上下文进行建模,使用局部令牌来执行令牌之间和令牌内的特征交互和探索。从而增强模块来增强局部特征,最后使用特征收缩解码器来对特征进行解码,得到最终的预测结果。
Transformer具有强大的全局视野,但是缺乏在局部区域内进行信息交互的机制,伪装目标总是和噪声对象和背景共享相似的外观信息,其中的微小差异很难通过低阶关系来区分,因此,本文提出了一种局部令牌增强模块来增强局部特征,从而增强局部特征的建模能力,同时保持全局特征的建模能力。首先采用非局部操作来交互相似的令牌,以聚合相邻的伪装线索,然后采用GCN运算来探索令牌内不同像素之间的高阶语义关系,以发现细微的判别特征。