
背景
目前物体检测算法有以下三种:
- 1.传统物体检测算法,使用人工设计特征以及机器学习的分类方式,但这种算法提取到的特征局限性较大且学习速度有限;
- 2.结合候选框+深度学习分类法,这类Two-Stage方法解决了前者的问题,在精度上有很大突破,但在速度上很难达到实时检测的效果;
- 3.基于深度学习的回归方法,在速度上达到了实时级别的突破,本文使用YOLO就是属于One-stage,YOLO虽然在v1,v2版本准确率上有所欠缺,但到v5版本时准确率提高了很多。
Yolo简介
① YOLO的全称是you only look once,指只需要浏览一次就可以识别出图中的物体的类别和位置。
② YOLO是目标检测模型。目标检测是计算机视觉中比较简单的任务,用来在一张图篇中找到某些特定的物体,目标检测不仅要求我们识别这些物体的种类,同时要求我们标出这些物体的位置。
③ YOLO能实现图像或视频中物体的快速识别,在相同的识别类别范围和识别准确率条件下,YOLO识别速度最快。YOLO有多种模型

yolov1
算法流程:
- 1.将输入图像缩放到$448\times448\times3$大小
- 2.经过卷积网络backbone提取特征图
- 3.把提取到的特征图输入到两层全连接层,最终输出$7\times7\times30$大小的特征图
检测方法:
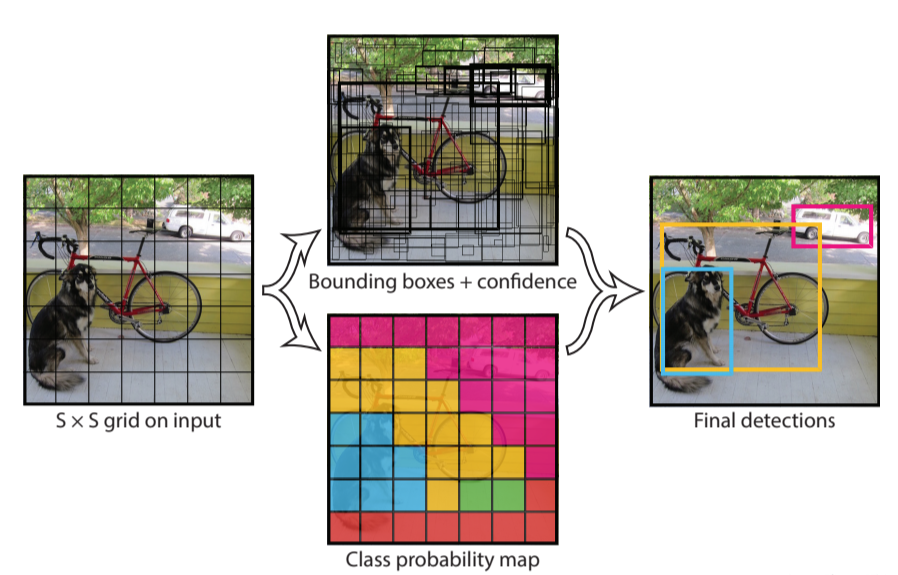
- 1.将输入图像划分成S*S的网格,如果物体中心落入某个网格内,就由该网格单元负责检测该目标。
- 2.每个网格预测B个边界框和它们的置信度,置信度是预测框和真实物体IOU和网格是否包含物体01值之积
- 3.每个边界框都包含5个预测值,x,y,w,h,confidence,分别代表中心坐标,宽高和IOU值,这里的坐标是相对于网格左上角的偏移量,宽高是相对于整幅图像的占比
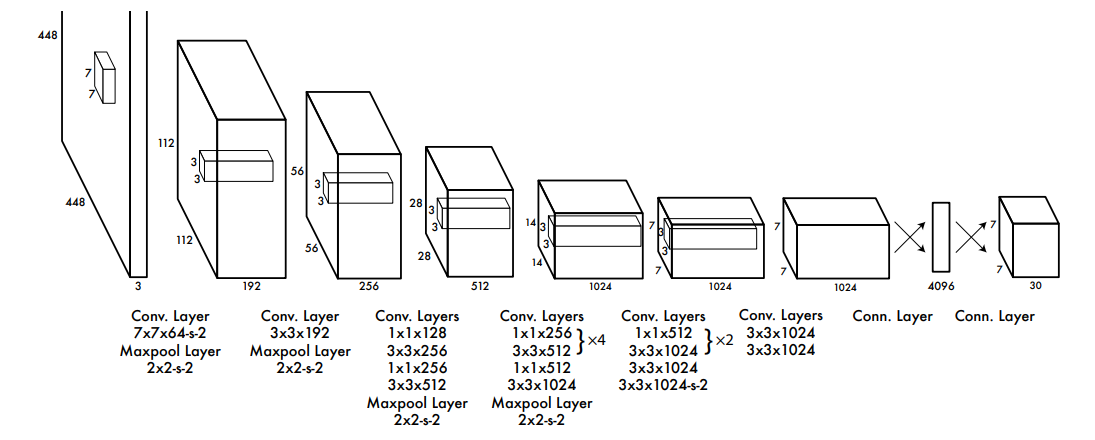
架构设计
网络前面的卷积层用于从图像中提取特征,全连接层用于预测输出概率和坐标,共有24个卷积层,2个全连接层。
Training设计
使用ImageNet分类数据先做预训练,预训练使用的网络为Fig 3中的前20层卷积,再加一个average-pooling层和全连接层。预训练好以后,再加4层卷积和2层全连接(随机初始化权重)去训练检测任务,输入大小为448×448,预训练分类时使用的是224×224。最后一层会同时输出类别概率和box的坐标,利用图像的宽和高对box的宽和高做归一化,使其介于0和1之间。将box的x和y坐标参数化为特定网格单元位置的偏移量,因此它们也在0和1之间。对最后一层使用线性激活函数,其他层均使用leaky ReLU。
优化模型输出的sum-squared error,是因为它很容易优化,但并不完全符合最大化average precision的目标。它将定位误差与分类误差同等加权,这可能并不理想。此外,图像中会有很多网格不包含任何目标,这些网格的confidence score为0,这通常会overpower确实包含目标的网格的梯度。这会导致模型不稳定,出现发散。为了解决这个问题,增加了bounding box坐标预测的损失,减小了不包含目标的box的confidence预测的损失,使用参数 $\lambda_{coord}(=5),\lambda_{noobj}(=0.5)$来完成
sum-squared error对大box和小box也是同等加权的,一个好的误差度量应该能反映出small box中的小偏差比large box的小偏差更重要。为了解决这个问题,使用bounding box的宽和高的平方根来计算,而不是宽和高本身。YOLO对每个网格单元会预测多个bounding boxes。在训练时,我们希望对每个目标只有一个bounding box预测器对其负责。会分配一个预测器来负责预测一个目标,基于它的预测与ground truth有最高的IOU。
YOLOV1优点
①快。因为回归问题没有复杂的流程(pipeline)。
②可以基于整幅图像预测(看全貌而不是只看部分)。与基于滑动窗口和区域提议的技术不同,YOLO在训练和测试期间会看到整个图像,因此它隐式地编码有关类及其外观的上下文信息。因为能看到图像全貌,与 Fast R-CNN 相比,YOLO 预测背景出错的次数少了一半。
③学习到物体的通用表示(generalizable representations),泛化能力好。因此,当训练集和测试集类型不同时,YOLO 的表现比 DPM 和 R-CNN 好得多,应用于新领域也很少出现崩溃的情况。
YOLOV1缺点
① 空间限制:一个单元格只能预测两个框和一个类别,这种空间约束必然会限制预测的数量;
② 难扩展:模型根据数据预测边界框,很难将其推广到具有新的或不同寻常的宽高比或配置的对象。由于输出层为全连接层,因此在检测时,YOLO 训练模型只支持与训练图像相同的输入分辨率。
③ 网络损失不具体:无论边界框的大小都用损失函数近似为检测性能,物体 IOU 误差和小物体 IOU 误差对网络训练中 loss 贡献值接近,但对于大边界框来说,小损失影响不大,对于小边界框,小错误对 IOU 影响较大,从而降低了物体检测的定位准确性。