
思想
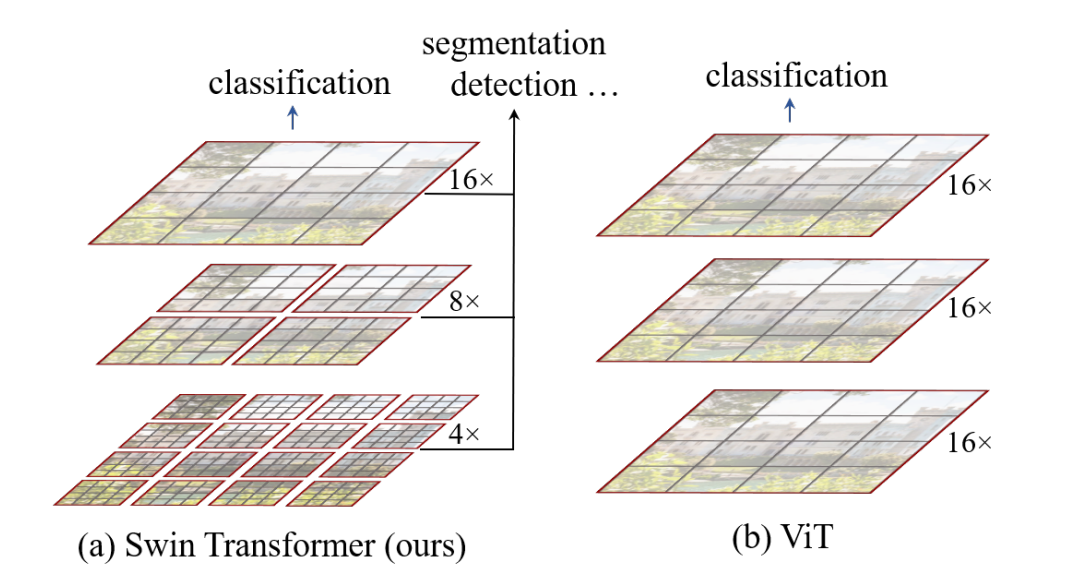 从上图中可以知道,swin有两个主要的特点
从上图中可以知道,swin有两个主要的特点
- 1:层级结构,类似于fpn,抽取不同层次的视觉特征,使其更适合分割检测任务,相比起VIT而言,swin有一个分辨率逐渐降低的过程,也就是图像中的4,8,16倍数的下采样,但是VIT则是一支保持16倍的下采样。
- 2:transformer范围不同,上图两边红框代表在红框内进行transformer,右边VIT的红框是整张图,而左边Swin Transformer的红框是在小窗口上进行的,也就是swin这个词的意思,在小窗口进行transformer,而非整张图。
架构
- 1.首先将图像输入到patch Partition模块中进行分块,也就是将相邻的$4\times4$的像素作为一个patch,然后再channel方向展开,假设输入的是RGB三通道,那么每个patch就有$4\times4=16$个像素,然后每个像素值有R,G,B三个值所以展开后有48个值,所以通过Patch Partition后图像shape由[H,W,3]变成了[H/4,W/4,48]。然后在通过Linear Embeding层对每个像素的channel数据做线性变换,由48变成C,即图像shape再由[H/4,W/4,48]变成了[H/4,W/4,C]
- 2.然后通过四个stage构建不同大小的特征图,除了stage1中通过一个Linear Embeding层外,剩下三个stage都是先通过一个Patch Merging层进行下采样。然后都是重复堆叠Swin Transformer Block注意这里的Block其实有两种结构,如图(b)中所示,这两种结构的不同之处仅在于一个使用了W-MSA结构,一个使用了SW-MSA结构。而且这两个结构是成对使用的,先使用一个W-MSA结构再使用一个SW-MSA结构。所以你会发现堆叠Swin Transformer Block的次数都是偶数
Patch Embedding
在输入进Block前,我们需要将图片切成一个个patch,然后嵌入向量。
具体做法是对原始图片裁成一个个 patch_size * patch_size的窗口大小,然后进行嵌入。这里可以通过二维卷积层,将stride,kernelsize设置为patch_size大小。设定输出通道来确定嵌入向量的大小。最后将H,W维度展开,并移动到第一维度
class PatchEmbed(nn.Module):
r""" Image to Patch Embedding
Args:
img_size (int): Image size. Default: 224.
patch_size (int): Patch token size. Default: 4.
in_chans (int): Number of input image channels. Default: 3.
embed_dim (int): Number of linear projection output channels. Default: 96.
norm_layer (nn.Module, optional): Normalization layer. Default: None
"""
def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]]
self.img_size = img_size
self.patch_size = patch_size
self.patches_resolution = patches_resolution
self.num_patches = patches_resolution[0] * patches_resolution[1]
self.in_chans = in_chans
self.embed_dim = embed_dim
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
if norm_layer is not None:
self.norm = norm_layer(embed_dim)
else:
self.norm = None
def forward(self, x):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x).flatten(2).transpose(1, 2) # B Ph*Pw C
if self.norm is not None:
x = self.norm(x)
return x
def flops(self):
Ho, Wo = self.patches_resolution
flops = Ho * Wo * self.embed_dim * self.in_chans * (self.patch_size[0] * self.patch_size[1])
if self.norm is not None:
flops += Ho * Wo * self.embed_dim
return flops
Patch Merging详解
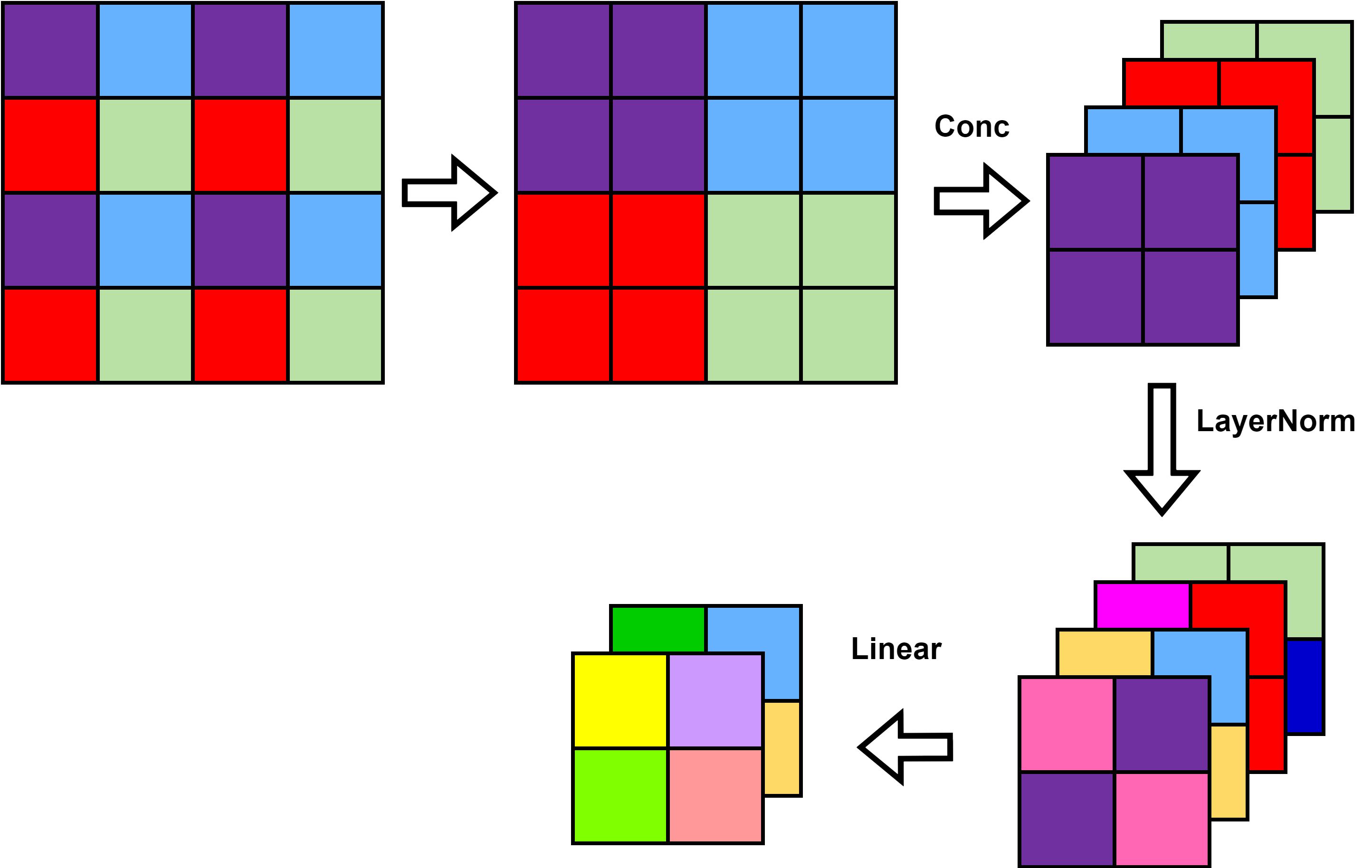
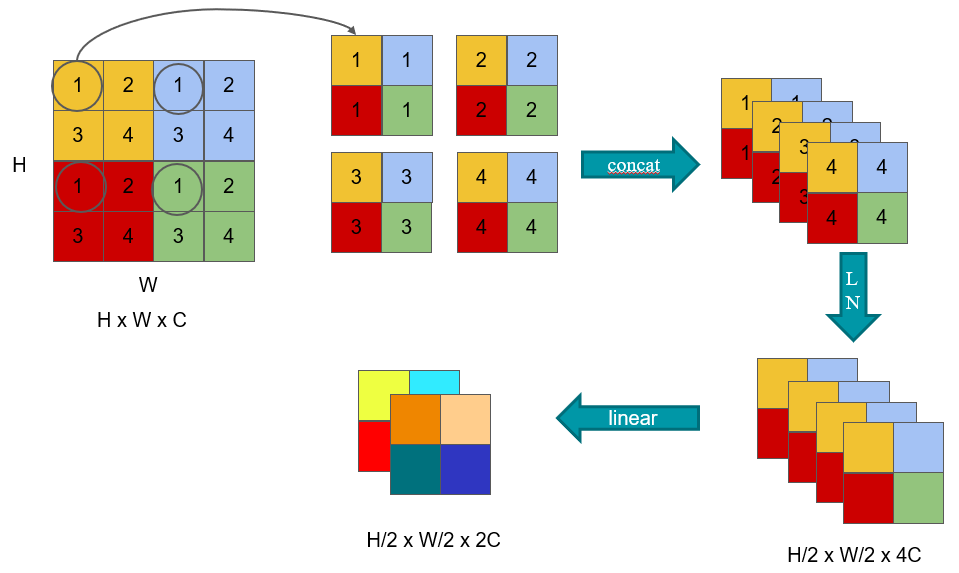 如上图所示,假设输入Patch Merging的是一个4x4大小的单通道特征图(feature map),Patch Merging会将每个2x2的相邻像素划分为一个patch,然后将每个patch中相同位置(同一颜色)像素给拼在一起就得到了4个feature map。接着将这四个feature map在深度方向进行concat拼接,然后在通过一个LayerNorm层。最后通过一个全连接层在feature map的深度方向做线性变化,将feature map的深度由C变成C/2。通过这个简单的例子可以看出,通过Patch Merging层后,feature map的高和宽会减半,深度会翻倍。
如上图所示,假设输入Patch Merging的是一个4x4大小的单通道特征图(feature map),Patch Merging会将每个2x2的相邻像素划分为一个patch,然后将每个patch中相同位置(同一颜色)像素给拼在一起就得到了4个feature map。接着将这四个feature map在深度方向进行concat拼接,然后在通过一个LayerNorm层。最后通过一个全连接层在feature map的深度方向做线性变化,将feature map的深度由C变成C/2。通过这个简单的例子可以看出,通过Patch Merging层后,feature map的高和宽会减半,深度会翻倍。
class PatchMerging(nn.Module):
r""" Patch Merging Layer.
Args:
input_resolution (tuple[int]): Resolution of input feature.
dim (int): Number of input channels.
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
该块包含了一个减少通道数的操作和一个归一化操作,输入分辨率为 input_resolution,特征维度为 dim。
在forward方法中,输入的特征张量 x 会被分成四个部分,每个部分都是原始张量的一部分,并且这四个部分会被拼接在一起。
然后,这个拼接后的张量会被归一化和减少通道数,最后返回结果张量。extra_repr方法用于返回该模块的一些额外信息,
flops 方法用于计算该模块的计算量。
"""
def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
self.norm = norm_layer(4 * dim)
def forward(self, x):
"""
x: B, H*W, C
输入参数x是一个形状为[B, HW, C]的张量,其中B表示batch size,H和W表示输入图像的高和宽,C表示输入通道数。
该函数首先将输入x的形状改变为[B, H, W, C],然后将输入的每个像素点分成四个小块(2x2),分别对每个小块进行操作,
并将结果在通道维度上拼接起来,得到一个形状为[B, H/2W/2, 4*C]的张量。接着,对这个张量进行归一化和降维操作,
最后返回结果。在函数执行过程中,还进行了一些检查,
例如检查输入特征的尺寸是否正确,以及输入图像的高和宽是否为偶数。
"""
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
assert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even."
x = x.view(B, H, W, C)
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
x = self.norm(x)
x = self.reduction(x)
return x
def extra_repr(self) -> str:
return f"input_resolution={self.input_resolution}, dim={self.dim}"
def flops(self):
H, W = self.input_resolution
flops = H * W * self.dim
flops += (H // 2) * (W // 2) * 4 * self.dim * 2 * self.dim
return flops
ps:LayerNorm层是一种归一化技术,主要作用是对神经网络中的每个样本进行归一化,使得每个样本的特征都具有相同的分布。具体来说,LayerNorm层会对每个样本的特征进行均值和方差的计算,并将其归一化为标准正态分布,从而使得每个样本的特征都具有相同的尺度和分布,从而提高神经网络的训练效果和泛化能力。此外,LayerNorm层还可以减轻梯度消失和梯度爆炸问题,提高神经网络的稳定性。
window Attention
计算方式:
$$\Large Attention(Q,K,V)=Softmax(\frac{QK^T}{\sqrt{d} }+B)V$$
为了实现多头Self-Attention,和传统的全局Self-Attention所不同,swin中引入了相对位置编码。
class WindowAttention(nn.Module):
r""" Window based multi-head self attention (W-MSA) module with relative position bias.
It supports both of shifted and non-shifted window.
Args:
dim (int): Number of input channels.
window_size (tuple[int]): The height and width of the window.
num_heads (int): Number of attention heads.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
proj_drop (float, optional): Dropout ratio of output. Default: 0.0
"""
def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim
self.window_size = window_size # Wh, Ww
self.num_heads = num_heads # nH
head_dim = dim // num_heads # 每个注意力头对应的通道数
self.scale = qk_scale or head_dim ** -0.5
# define a parameter table of relative position bias
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # 设置一个形状为(2*(Wh-1) * 2*(Ww-1), nH)的可学习变量,用于后续的位置编码
# get pair-wise relative position index for each token inside the window
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index",relative_position_index)
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
trunc_normal_(self.relative_position_bias_table, std=.02)
self.softmax = nn.Softmax(dim=-1)
# 相关位置编码...
def forward(self, x, mask=None):
"""
Args:
x: input features with shape of (num_windows*B, N, C)
mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
"""
B_, N, C = x.shape
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
attn = attn + relative_position_bias.unsqueeze(0)
if mask is not None:
nW = mask.shape[0]
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
相对位置编码
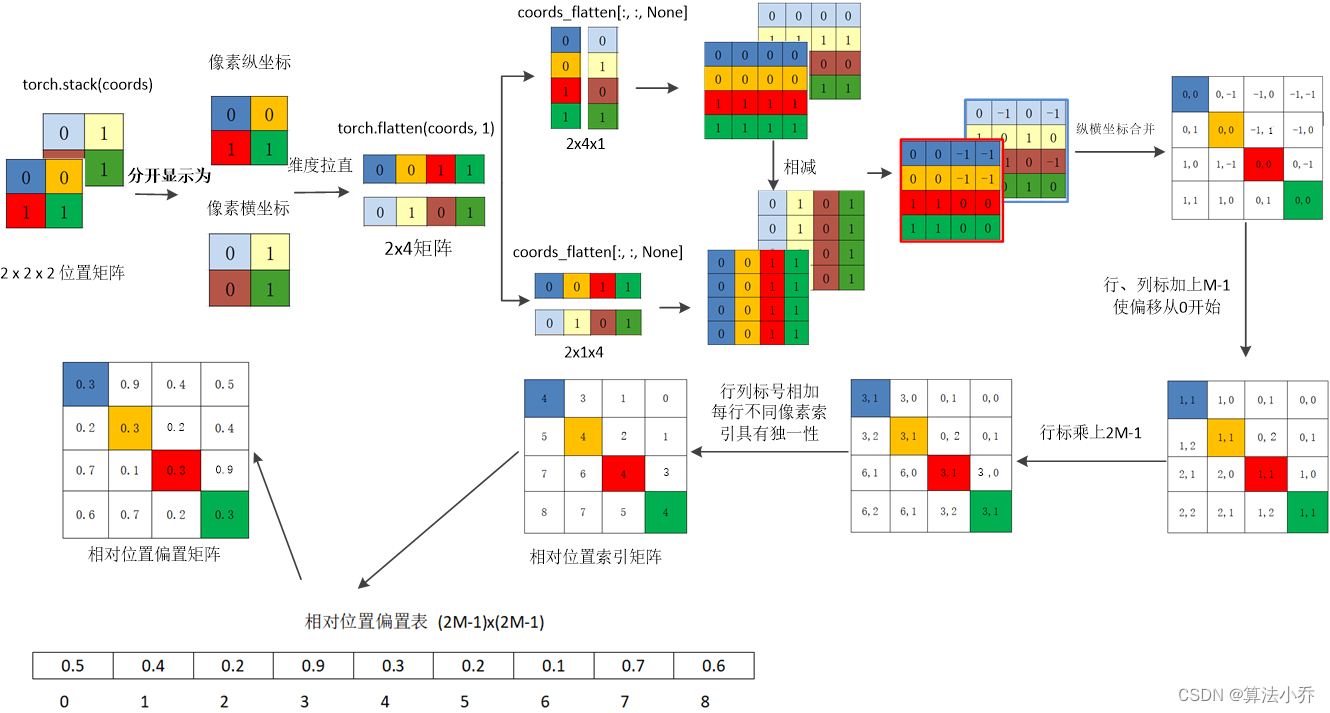 上文公式中的B就是我们这里讲到的相对位置编码矩阵。
Swin Transformer中的相对位置编码是通过计算两个位置之间的相对距离来实现的。具体来说,Swin Transformer使用了一种新的相对位置编码方法,称为Swin Transformer Position Encoding(STE)。
STE的基本思想是将输入序列划分为多个块,并在每个块中计算相对位置编码。每个块的大小由一个参数P控制,通常设置为16或32。在每个块中,Swin Transformer使用一个可学习的相对位置编码矩阵来计算相对位置编码。
具体来说,假设我们有一个输入序列X,其长度为N,块大小为P。我们将输入序列划分为N/P个块,每个块包含P个元素。对于每个块i,Swin Transformer计算相对位置编码矩阵Ri,其大小为P x P。然后,对于块i中的每个元素j,Swin Transformer计算其相对位置编码向量Eij,其大小为1 x P。Eij是通过将元素j与块中所有其他元素的距离作为输入,通过一个前馈神经网络计算得到的。
最后,Swin Transformer将每个相对位置编码向量Eij与相对位置编码矩阵Ri相乘,得到最终的相对位置编码向量Pij,其大小为1 x P。Pij表示元素j与块i中所有其他元素之间的相对位置编码。在进行自注意力计算时,Swin Transformer使用Pij来计算每个元素的注意力权重。
总之,Swin Transformer中的相对位置编码是通过将输入序列划分为多个块,并在每个块中计算相对位置编码矩阵和相对位置编码向量来实现的。这种方法可以有效地处理较长的序列,并且可以通过学习自适应地计算相对位置编码。
上文公式中的B就是我们这里讲到的相对位置编码矩阵。
Swin Transformer中的相对位置编码是通过计算两个位置之间的相对距离来实现的。具体来说,Swin Transformer使用了一种新的相对位置编码方法,称为Swin Transformer Position Encoding(STE)。
STE的基本思想是将输入序列划分为多个块,并在每个块中计算相对位置编码。每个块的大小由一个参数P控制,通常设置为16或32。在每个块中,Swin Transformer使用一个可学习的相对位置编码矩阵来计算相对位置编码。
具体来说,假设我们有一个输入序列X,其长度为N,块大小为P。我们将输入序列划分为N/P个块,每个块包含P个元素。对于每个块i,Swin Transformer计算相对位置编码矩阵Ri,其大小为P x P。然后,对于块i中的每个元素j,Swin Transformer计算其相对位置编码向量Eij,其大小为1 x P。Eij是通过将元素j与块中所有其他元素的距离作为输入,通过一个前馈神经网络计算得到的。
最后,Swin Transformer将每个相对位置编码向量Eij与相对位置编码矩阵Ri相乘,得到最终的相对位置编码向量Pij,其大小为1 x P。Pij表示元素j与块i中所有其他元素之间的相对位置编码。在进行自注意力计算时,Swin Transformer使用Pij来计算每个元素的注意力权重。
总之,Swin Transformer中的相对位置编码是通过将输入序列划分为多个块,并在每个块中计算相对位置编码矩阵和相对位置编码向量来实现的。这种方法可以有效地处理较长的序列,并且可以通过学习自适应地计算相对位置编码。
其中的随机生成的$(2M-1) \times (2M-1)$ 的相对位置偏置是一组可学习的参数
W-MSA
W-MSA:Windows Multi-head Self-Attention多头窗口自注意力
目的:减少计算量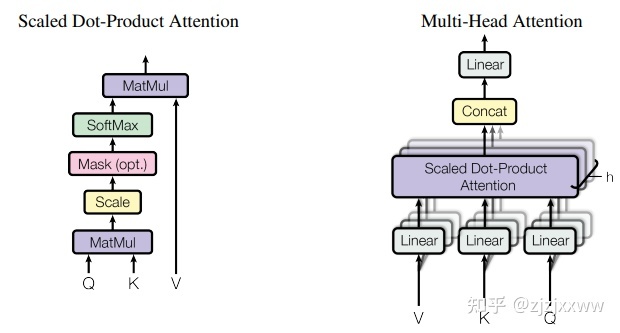
对于普通的MSA模块,feature map中的每个像素与class序列在Self-attention计算过程中需要和所有的像素去计算全局,但是使用W-MSA时,将会将feature map拆分为一个个不重叠的window,比如是$M\times M$大小的windows,然后单独对每个windows内部进行Self-Attention。假设在Swin transformer中输入$224\times224\times3$的图片,那么一个patch的大小划分为$4\times4$,那么就有$56\times56$个patch,而每7个patch就组成一个窗口,也就是一个窗口有$7\times7$个patch,一个$224\times224\times3$的图片会有$8\times 8=64$个窗口。论文中给出的具体计算公式为:
$$\Large \Omega(MSA)=4hwC^2+2(hw)^2C$$
$$\Large \Omega(W-MSA)=4hwC^2+2M^2hwC$$
h代表feature map的高度
w代表feature map的宽度
C代表feature map的深度
不难发现其中变化的就是将原有的feature map全部遍历所带来的复杂度$(hw)^2$变成了遍历$M\times M$的Windows复杂度$M^2hw$。看似差别不大,但是实际上差了几十倍甚至上百倍。
SW-MSA
当只有W-MSA时,只会有每个窗口内部进行Self-Attention,窗口之间是无法实现信息的传递的。为了实现窗口之间高效的相互交互,作者提出了Shifted Windows Multi-Head Self-Attention(SW-MSA)模块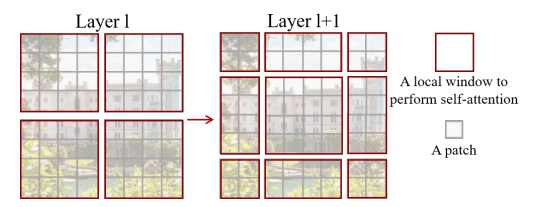
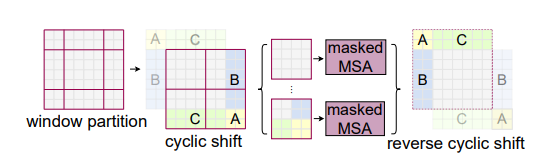
其中layer1表示原本的分块,然后将窗口向右下角滑动一个$2\times2$的位置得到layer2,然后再进行Attention操作,但是直接这样处理会带来一个问题就是当原本不在一起的图像块也会进行attention操作,这是不合理的,这时候我们就需要想办法让其能知道,当shift之后,哪些块原本是相邻的,哪些是原本不相邻的。这时候引入下图所示的mask机制,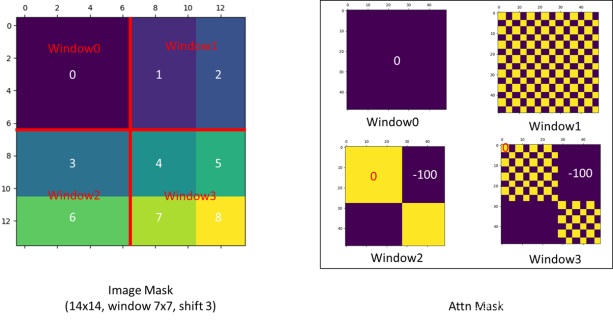
使用矩阵的方式将不相邻的块变为图像中的紫色,置位负无穷大,使得在进行softmax时可以将其变为0,也就相当于是没有进行attention操作。
此时一个基础的SwinTransformerBlock就构建完毕了。
class SwinTransformerBlock(nn.Module):
r""" Swin Transformer Block.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resulotion.
num_heads (int): Number of attention heads.
window_size (int): Window size.
shift_size (int): Shift size for SW-MSA.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float, optional): Stochastic depth rate. Default: 0.0
act_layer (nn.Module, optional): Activation layer. Default: nn.GELU
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
fused_window_process (bool, optional): If True, use one kernel to fused window shift & window partition for acceleration, similar for the reversed part. Default: False
"""
def __init__(self, dim, input_resolution, num_heads, window_size=7, shift_size=0,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0., drop_path=0.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm,
fused_window_process=False):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.num_heads = num_heads
self.window_size = window_size
self.shift_size = shift_size
self.mlp_ratio = mlp_ratio
if min(self.input_resolution) <= self.window_size:
# if window size is larger than input resolution, we don't partition windows
self.shift_size = 0
self.window_size = min(self.input_resolution)
assert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"
self.norm1 = norm_layer(dim)
self.attn = WindowAttention(
dim, window_size=to_2tuple(self.window_size), num_heads=num_heads,
qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
if self.shift_size > 0:
# calculate attention mask for SW-MSA
H, W = self.input_resolution
img_mask = torch.zeros((1, H, W, 1)) # 1 H W 1
h_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
mask_windows = window_partition(img_mask, self.window_size) # nW, window_size, window_size, 1
mask_windows = mask_windows.view(-1, self.window_size * self.window_size)
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
else:
attn_mask = None
self.register_buffer("attn_mask", attn_mask)
self.fused_window_process = fused_window_process
def forward(self, x):
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
shortcut = x
x = self.norm1(x)
x = x.view(B, H, W, C)
# cyclic shift
if self.shift_size > 0:
if not self.fused_window_process:
shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
# partition windows
x_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, C
else:
x_windows = WindowProcess.apply(x, B, H, W, C, -self.shift_size, self.window_size)
else:
shifted_x = x
# partition windows
x_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, C
x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # nW*B, window_size*window_size, C
# W-MSA/SW-MSA
attn_windows = self.attn(x_windows, mask=self.attn_mask) # nW*B, window_size*window_size, C
# merge windows
attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C)
# reverse cyclic shift
if self.shift_size > 0:
if not self.fused_window_process:
shifted_x = window_reverse(attn_windows, self.window_size, H, W) # B H' W' C
x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
else:
x = WindowProcessReverse.apply(attn_windows, B, H, W, C, self.shift_size, self.window_size)
else:
shifted_x = window_reverse(attn_windows, self.window_size, H, W) # B H' W' C
x = shifted_x
x = x.view(B, H * W, C)
x = shortcut + self.drop_path(x)
# FFN
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
最后就是按架构图所设计的将四个block给堆叠起来得到完整的swin-transformer。