
Mask TextSpotter
该文受到Mask R-CNN的启发提出了一种用于场景text spotting的可端到端训练的神经网络模型:Mask TextSpotter。与以前使用端到端可训练深度神经网络完成text spotting的方法不同,Mask TextSpotter利用简单且平滑的端到端学习过程,通过语义分割获得精确的文本检测和识别。此外,它在处理不规则形状的文本实例(例如,弯曲文本)方面优于之前的方法。
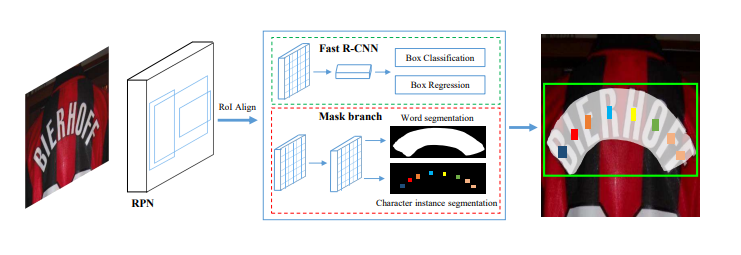
网络架构由四部分组成,骨干网feature pyramid network (FPN),文本候选区域生成网络region proposal network (RPN),文本包围盒回归网络Fast R-CNN,文本实例分割与字符分割网络mask branch。
训练阶段
RPN首先生成大量的文本候选区域,然后这些候选区域的RoI特征被送入Fast R-CNN branch和mask branch,由它们去分别生成精确的文本候选包围盒(text candidate boxes)、文本实例分割图(text instance segmentation maps)、字符分割图(character segmentation maps)。它将输入的RoI(固定大小$16\times64$)经过4层卷积层和1层反卷积层,生成38通道的图(大小$32\times128$),包括一个全局文本实例图——它给出了文本区域的精确定位,无论文本排列的形状如何它都能分割出来,还包括36个字符图(对应于字符0~9,A~Z),一个字符背景图(排除字符后的的所有背景区域),在后处理阶段字符背景图会被用到。
推理阶段mask branch的输入RoIs来自于Fast R-CNN的输出。
推理的过程如下:首先输入一幅测试图像,通过Fast R-CNN获取候选文本区域,然后通过NMS(非极大抑制)过滤掉冗余的候选区域,剩下的候选区域resize后送入mask branch,得到全局文本实例图,和字符图。通过计算全局文本实例图的轮廓可以直接得到包围文本的多边形,通过在字符图上使用提出的pixel voting方法生成字符序列。
如上图所示,Pixel voting方法根据字符背景图中每一个联通区域,计算每一字符层相应区域的平均字符概率,即得到了识别的结果。
为了在识别出来的字符序列中找到最佳匹配单词,作者在编辑距离(Edit Distance)基础上发明了加权编辑距离(Weighted Edit Distance)