
Multi-Scale High-Resolution Vision Transformer for Semantic Segmentation
摘要
VITs主要是为生成低分辨率表示的图像分类任务而设计的,这使得VITs的语义分割等密集预测任务具有挑战性,本文提出的HRVIT,通过高分辨率多分枝架构与ViT集成来增强ViT以学习语义丰富和空间精确的多尺度表示,通过各种分支块协同优化技术平衡HRVIT的模型行恩那个和效率
Introduction
VIT的单尺度和低分辨率表示对于需要高敏感性和细粒度图像细节的语义分割不友好。已有的多尺度VIT网络大多遵循类似于分类的网络拓扑,具有顺序或串联架构,基于复杂性考虑,都是逐渐对特征图进行下采样,以提取更高级别的低分辨表示,并将每个阶段的输出直接馈送到下游分割头,这样的顺序结构缺乏足够的跨尺度交互,因此没法产生高质量的高分辨率表示
HRVIT并行提取多分辨率特征并反复融合它们以生成具有丰富语义信息的高质量HR表示。简单的将HRNET中所有的卷积残差块替换为Transformer将遇到严重的可扩展性问题,如果没有良好的架构块协同优化,从多尺度继承的高表示能力可能会被硬件上令人望而却步的延迟和能源成本所击倒。因此本文使用以下方式进行优化
- 1)HRViT的多分支HR架构在跨分辨率融合的同时提取多尺度特征
- 2)使用增强局部注意力消除率冗余键和值以提高效率,并通过额外的并行卷积路径,额外的非线性单元和用于特征多样性增强的辅助快捷方式来增强模型的表达能力。
- 3)HRViT采用混合尺度卷积前馈网络加强多尺度特征提取
- 4)HRVIT的HR卷积结构和高效的补丁嵌入层在降低硬件成本的情况下保持率更多的低级细粒度特征
HRViT网络结构图
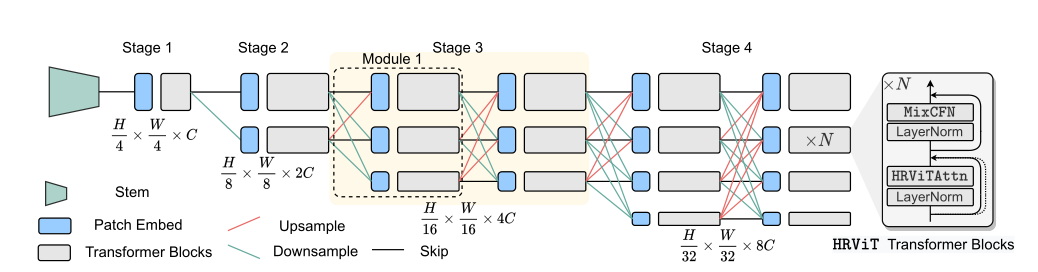
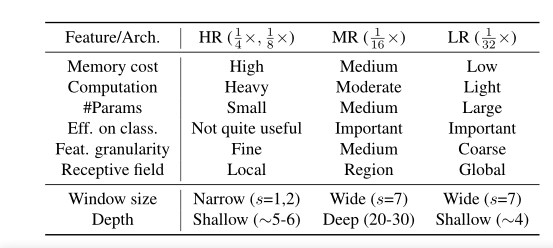
多分支HRNet和self-attention运算所带来的高度复杂性会迅速导致内存占用,参数大小急剧上升,计算成本爆炸性增长,简单地在每个模块上分配相同局部注意力窗口大小的块将导致巨大的计算成本,根据对于复杂性分析,
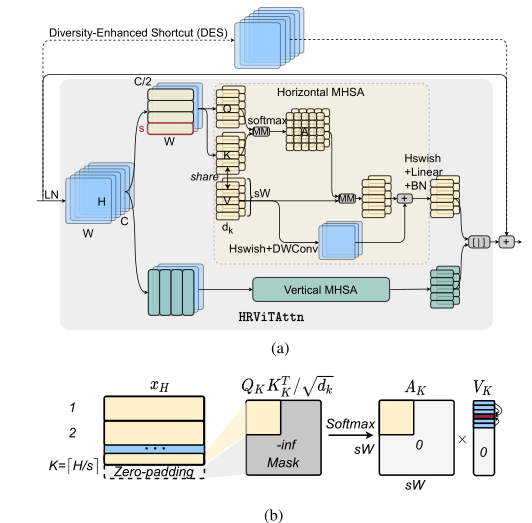
cross-shaped self-attention
- 细粒度注意力
- 近似全局视图:通过两个平行正交的局部注意力,能够收集全局信息
- 可伸缩复杂性:窗口是一个维度固定的,避免了图像大小的二次复杂性
遵循CSWin中的十字形窗口划分方法,将输入$x\in R^{H\times W\times C}$分成两部分${x_H,x_V \in R^{H\times W\times C/2}}$,$x_H$被分割成不相交的水平窗口,而另外一半$x_V$被分割成垂直窗口。将窗口设置为$s\times W$或者$H\times s$,在每个窗口中,将补丁分块为$K$个$d_k$维头部,然后应用局部self-attention。将零填充应用于输入$x_H$或$x_V$,以允许完整的第k个窗口,然后将注意力图中的填充区域屏蔽为0,以避免不连贯的语义关联
原始的QKV线性层在计算和参数方面非常昂贵,因此共享键和值张量的线性投影,以节省计算和参数,此外,引入一个辅助路径,该路径具有并行深度方向卷积,以注入归纳偏置以促进训练,与CSWin中的局部位置编码不同,我们的并行路径是非线性的,并且在没有窗口划分的情况下应用于整个4—D特征映射$W^Vx$而没有窗口分区,这条路径可以被视为一个反向残差模块,它与self-attention中的线性投影层共享逐点卷积。这种共享路径可以有效注入归纳偏差,并以边际硬件开销的情况下增强局部特征聚合,作为对上述键值共享的性能补偿,引入一个额外的Hardswish函数来改善非线性,附加一个初始化为恒等投影的BatchNorm层以稳定分布以获得更好的可训练性,此外还添加了一个通道式投影作为多样性增强快捷方式,与传统增强的快捷方式不同,此快捷方式具有更高的非线性,不依赖于对硬件不友好的傅里叶变换。
混合尺度卷积前馈网络
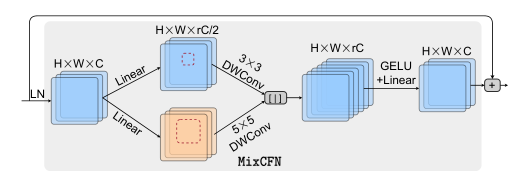
受到MIT的MIxFFN和HR-NAS中多分支倒置残差块的启发,我们通过在两个线性层之间插入多个尺度深度卷积路径来设计混合尺度卷积,在MiXCFN中,在LayerForm之后,我们将信道按r的比例展开,然后将其分成两个分支,$3\times 3$和$5 \times 5$深度方向卷积用于增加HRViT的多尺度局部信息提取,出于效率的考虑,我们利用信道冗余,将MiXCFN扩展比r从4降到3或者2,
下采样部分
self-attention的复杂度与图像大小成二次方,为解决大图像是的可伸缩性问题,在输入端对图像进行4倍的下采样,不在stem中使用注意操作,因为早期卷积比self-attention更能有效的提取低级特征,作为早期的卷积,遵循HRNet中的设计,并使用两个步长为2的CONV-BNReLU块作为更强的下采样stem,以提取C通道特征,并保留更多信息,这与之前使用步长为4的卷积ViTs不同.
在每个模块中的Transformer块之前,我们在分支上添加一个补丁嵌入块,用于匹配通道并通过增强的补丁之间通信提取补丁信息,但是n阶段的每个模块将会有n个嵌入块所带来的巨大算力代价,我们将补丁嵌入简化为逐点CONV,然后是深度CONV。
交叉分辨率融合,在每个模块的开头插入重复的交叉分辨率融合层。为了帮助LR特征保持更多的图像细节和精准的位置信息,我们将它们与下采样的HR特征合并,不使用基于渐进卷积的下采样路径来匹配张量形状,而是采用直接下采样路径来最小化算力开销,在第i个输入和第j个输出之间的下采样路径中,使用步长为$2j-i$的深度可分离卷积来缩小空间维度并匹配输出通道。
多尺度ViT分层架构来逐步下采样的金字塔特征。PVT将金字塔结构集成到ViT中以进行多尺度特征提取,Twins交织局部和全局注意力以学习多尺度表示,SegFormer提出了一种有效的分层编码器来提取粗略和精细的特征,CSWin通过多尺度十字形局部注意力进一步提高性能。
用于语义分割的多尺度表示学习:原有的分割框架是逐步对特征图进行下采样以计算LR表示,并通过上采样恢复HR特征,例如SegNet,UNet,Hourglass,HRNet通过跨分辨率融合在整个网络中维护HR表示,Lite-HRNet提出了条件通道加权块来跨分辨率交换信息,HR-NAS搜索反转残差块和辅助Transformer分支的通道